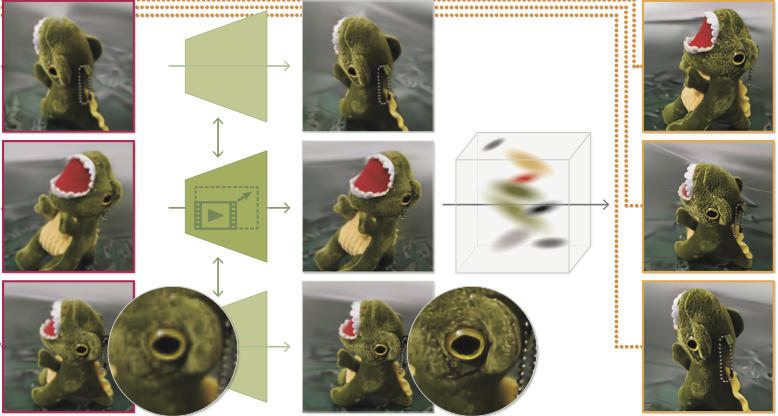

The videos below show the 16× upsampling result of our method (right) when applied to the low-resolution input (left). The videos are synchronized, such that the same frame is shown at the same time. We provide an interactive zoom lens to better appreciate the differences between low-res input and our output. The zoomed in views are enlarged by a factor of 2.5, showing the output at approximately the native video resolution (1024×1024px).
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)
low-res (64×64)
2.5×
3D Upsampled (1024×1024)